✅ 오늘의 파쓰 지식 : 오늘은 신뢰할 수 있는 A/B 테스트를 만들기 위해 실험 설계와 수행 과정에서 주의할 점들, 그리고 실험 전 편향을 극복하는 방법에 대해 알아보아요!
✅ 파쓰가 전하는 테크 샤라웃 : SK플래닛, 요기요, 컬리의 테크 블로그 소식을 소개합니다! |
|
|
A/B 테스트는 플랫폼을 개선하고 사용자가 무엇을 선호하는지 알아내기 위한 대표적인 방법이에요. 이 테스트는 제품의 기능이나 서비스에 작은 변화를 주고, 그 결과를 비교 분석함으로써 제품을 점진적으로 발전시키는 도구로 활용돼요. 특히 고객 중심으로 제품을 개선하려는 온라인 서비스 기업에겐 정말 중요한 도구라고 할 수 있어요.
마이크로소프트, 구글, 아마존, 넷플릭스, 에어비앤비 같은 해외 빅테크 기업들이 선보인 혁신적인 제품 개선 사례들 중에는 A/B 테스트가 없었다면 세상에 나오지 못했을 아이디어도 많았을 거예요. 빅테크 기업들은 A/B 테스트라는 온라인 통제 실험을 더 신뢰할 수 있고 효율적인 방식으로 수행하기 위해 지금도 끊임없이 연구하고 있어요.
하지만 때로는 이런 실험이 믿음직하지 않게 느껴질 때도 있어요. 결과가 너무 빨리 나오거나, 테스트 그룹과 통제 그룹 간 조건이 달라지는 문제가 생기기도 하거든요. 모든 실험이 그렇듯, A/B 테스트도 제대로 다루는 게 중요해요. 그래서 오늘은 신뢰할 수 있는 A/B 테스트를 만들기 위해 실험 설계와 수행 과정에서 주의할 점, 그리고 실험 전에 편향을 극복하는 방법에 대해 이야기해 보려고 해요.
|
|
|
먼저, A/B 테스트가 무엇인지 간단히 알아볼까요? 😊 A/B 테스트는 제품의 두 가지 버전을 사용자에게 보여주고, 어떤 버전이 더 나은 성과를 내는지 비교하는 실험 방법이에요. 예를 들어, 버튼 색상을 파란색(A 버전)과 빨간색(B 버전)으로 나눠 각각의 클릭 수를 비교하거나, 새 기능이 포함된 페이지와 기존 페이지의 사용자 반응을 측정하는 방식이에요.
이 테스트의 장점은 데이터 기반으로 결정을 내릴 수 있게 해준다는 점이에요. 단순히 직관이나 감각에 의존하는 게 아니라, 실제 사용자가 보여준 행동 데이터를 바탕으로 개선 방향을 설정할 수 있죠. 그래서 A/B 테스트는 기능 최적화나 UX 개선에서 중요한 역할을 하고, 많은 플랫폼 메이커들이 의사결정 도구로 활용하고 있어요.
|
|
|
왜 A/B 테스트의 신뢰성이 중요한가요?🤷♂️ |
|
|
플랫폼의 성과를 평가하고 나아갈 방향을 결정하는 데 있어 A/B 테스트는 필수적인 도구로 자리 잡고 있어요. 특히 구독자와의 상호작용을 기반으로 하는 서비스에서는 정확한 실험 결과가 의사결정에 큰 영향을 미치죠. 하지만 이러한 테스트를 설계하는 과정에서 잘못된 편향*이 들어가면, 그 결론 또한 오류로 이어질 수 있어요. 이렇게 되면 의사결정이 잘못될 뿐 아니라 사용자 경험에도 부정적인 영향을 미칠 수 있답니다.
*편향이란 무엇일까요?
편향이란 실험에 참여한 사용자 그룹이 한쪽으로 치우쳐져 있는 상태를 의미해요. 예를 들어, A/B 테스트를 진행할 때 특정 연령대나 특정 지역 사용자가 한 그룹에 몰리게 되면, 그 그룹의 특성 때문에 결과가 왜곡될 수 있어요. 이럴 경우, A/B 테스트에서 더 나은 결과를 보인 쪽이 모든 사용자에게 효과적인 것이 아닐 수 있답니다.
|
|
|
신뢰할 수 있는 A/B 테스트를 위해 피해야 할 함정들🕳️ |
|
|
A/B 테스트는 개념적으로 간단해 보일 수 있지만, 사용자 그룹 설정, 분기 처리, 로깅, 데이터 수집 및 처리, 그리고 의사결정에 이르기까지 다양한 오류가 발생할 가능성이 있어요. 그렇기 때문에 신뢰할 수 있는 실험 결과를 얻으려면 가설 검증을 수행하는 분석 단계뿐만 아니라, 실험 전 과정에서 여러 요소에 세심한 주의를 기울이는 것이 중요하답니다.
그렇다면 A/B 테스트를 수행할 때 단계별로 발생할 수 있는 실험 편향과 함정은 무엇인지, 그리고 이를 어떻게 해결할 수 있는지 함께 알아볼까요?
|
|
|
1. 실험 설계 단계: 사용자 그룹 설정의 함정
실험과 통제 집단이 완전한 무작위로 나뉘지 않는 경우가 많아요. 특정 사용자 유형이 한쪽 집단에 몰리면, 그 집단의 특성으로 인해 실험 결과에 편향이 생길 수 있어요.
A/A 테스트나 층화 추출(stratified sampling) 같은 방법을 활용할 수 있어요. A/A 테스트는 실험과 통제 집단이 제대로 나뉘었는지 확인하는 데 유용하고, 층화 추출을 통해 주요 변수에 따라 각 그룹이 비슷한 특성을 가질 수 있도록 설계할 수도 있죠.
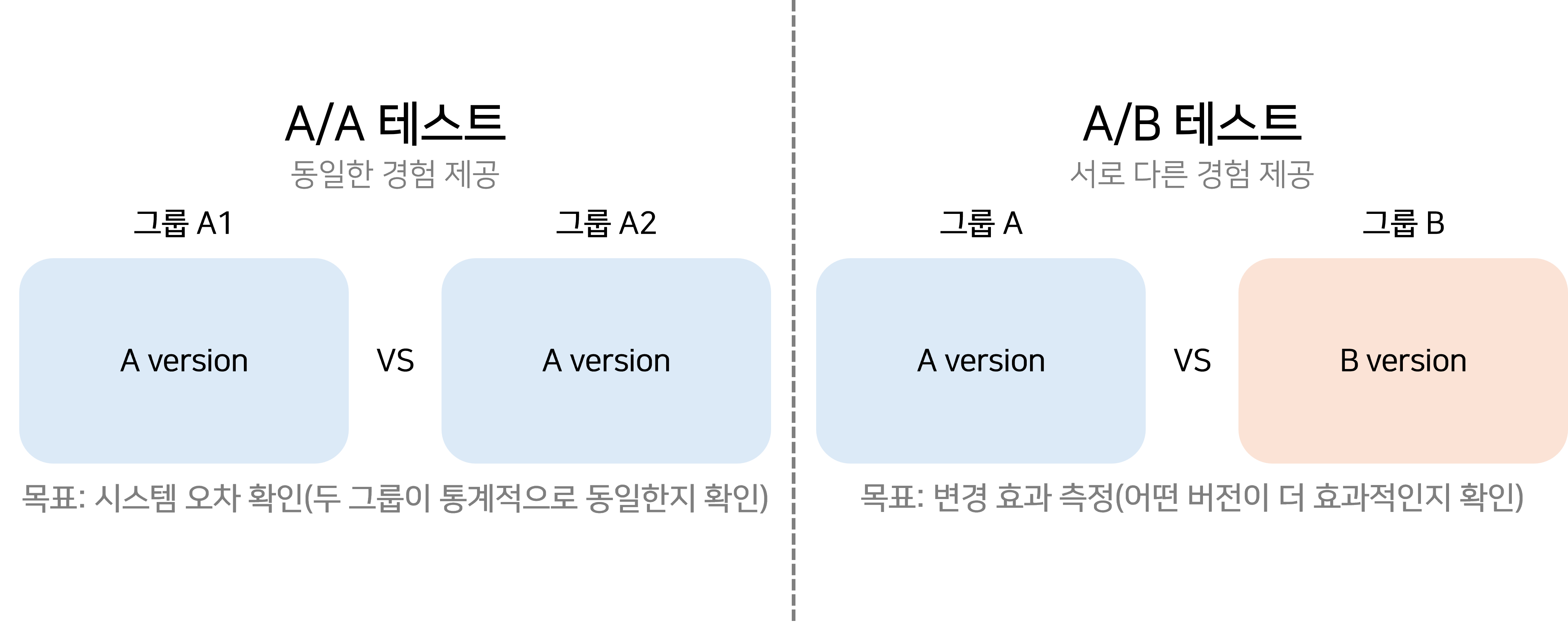
✔️A/A 테스트
A/A 테스트는 실험과 통제 집단 모두에게 동일한 경험을 제공하여 집단 간 차이가 없는지를 확인하는 방법이에요. 즉, 두 버전 간에 차이가 발생해야 유의미한 결과로 볼 수 있는 A/B 테스트와는 달리 A/A 테스트는 두 버전 간에 차이가 없어야만 유의미한 결과로 볼 수 있어요.
A/A 테스트의 주된 목적은 실험 시작 전 편향을 사전에 잡아주어, 이후 진행되는 A/B 테스트 결과의 신뢰도를 높이는 것이에요. 즉, 실험 전에 통제 집단의 무작위 배정이 잘 이루어졌는지 확인하는 데 도움을 줄 수 있어요.
예를 들어, 과거 데이터를 활용하여 각 군의 편향을 체크하거나, 실제로 실험 환경에서 1~2주간 테스트를 진행해 실험 조건이 유사한지 확인하는 용도로 활용돼요. 다만, 실제 실험 시작까지 시간이 지연될 수 있다는 단점이 있어요.
|
|
|
<A/A테스트와 A/B테스트의 차이, 출처:INF Academy>
|
|
|
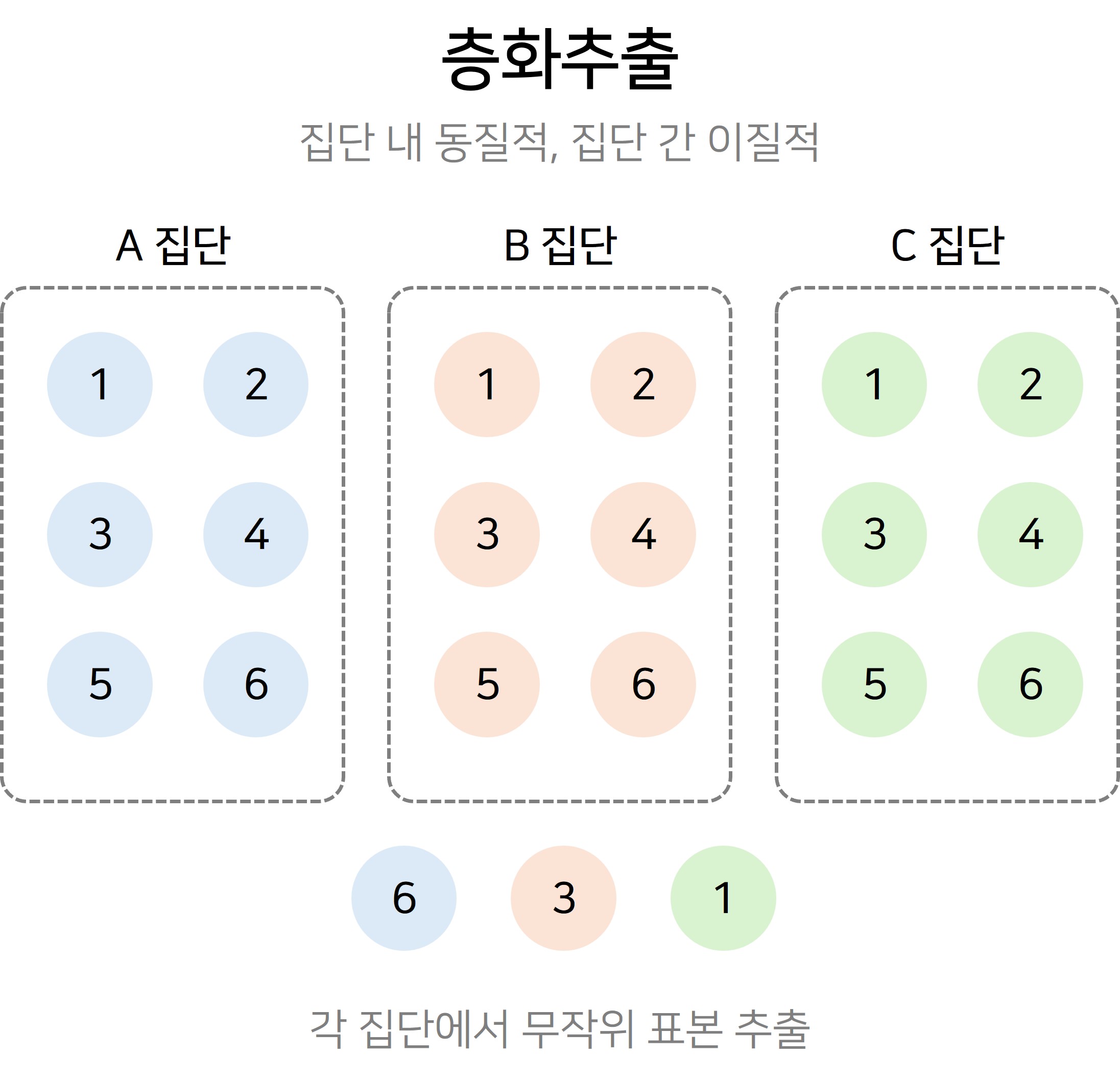
✔️층화 추출(stratified sampling)
층화 추출은 모집단을 주요 특성에 따라 여러 개의 하위 집단(층)으로 나눈 후, 각 층에서 표본을 추출하는 방법이에요. 예를 들어, 연령, 성별 등의 특성에 따라 여러 층으로 나누고 각 층에서 표본을 무작위로 추출하는 방식이죠. 이를 통해 각 그룹이 유사한 특성을 가지도록 설정하여 편향을 줄일 수 있어요.
다만, 모집단을 다양한 특성(예: 성별, 연령, 지역 등)으로 층을 나누는 과정이 필요하기 때문에, 이 과정에서 적절한 층을 설정하기 위해 많은 시간과 자원이 필요해요. 특히 모집단에 대한 사전 정보가 충분하지 않으면 층 구분 자체가 어려울 수 있죠.
또한 층화된 그룹마다 표본을 추출하는 과정에서 모집단의 각 층에 대한 별도 목록과 데이터를 준비해야 하기 때문에 단순 무작위 추출보다 더 많은 비용이 소요될 수 있어요. 즉, 층화 추출법은 모집단을 잘 이해하고 층화 기준이 명확할 때 가장 효과적인 방법이에요!
|
|
|
<층화추출 방법, 출처:INF Academy>
|
|
|
2. 실험 수행 단계: 실험 분기와 데이터 수집의 문제
실험 수행 단계에서는 실험 군과 통제 군 간의 분기가 잘 이루어지지 않거나, 사용자 로그가 누락되는 일이 생각보다 자주 발생할 수 있는데요. 이런 오류는 작은 실수처럼 보여도 실험 결과에 큰 영향을 미칠 수 있어요.
예를 들어, 동일한 사용자가 실험 군과 통제 군에 동시에 포함되거나, 쿠키 기반 분기 설정이 제대로 작동하지 않는 경우가 있을 수 있어요. 이를 방지하기 위해서는 분기 로직을 사전에 철저히 점검하는 것이 중요해요. 특히 A/B 테스트 도구(예: Optimizely, Google Optimize, VWO 등)가 올바르게 설정되어 있는지 확인하고, 테스트 시작 전에 분기 상태를 소규모로 실험해 보는 것도 좋은 방법이에요.
또 하나 중요한 부분은 데이터 품질 관리인데요. 실험 중 수집된 로그 데이터가 정확하게 누락 없이 잘 저장되었는지 주기적으로 검증하는 과정이 필요해요. 데이터 수집 단계에서 노이즈가 섞이거나 일부 데이터가 유실되면 실험 결과의 신뢰도가 크게 떨어질 수 있기 때문이에요. 이러한 문제를 방지하기 위해서는 실시간 로그 분석 도구나 데이터 검증 체크리스트를 활용하면 좋아요. 이를 통해 수집된 데이터를 정제하고, 유효한 샘플만 사용하도록 관리한다면 실험의 신뢰도가 훨씬 높아질 수 있을 거예요. |
|
|
3. 실험 분석 단계: 분석 기준과 유의성 검증
분석 기준 지표를 사전에 명확하게 정의하지 않거나, 분석 후 유의성 검증을 제대로 하지 않으면 실험 결과의 신뢰도가 떨어질 수 있어요. 예를 들어, 클릭률, 전환율, 잔존율 중 어떤 지표를 기준으로 삼을 것인지 정하지 않고 분석을 시작하면, 서로 다른 해석이 나올 수 있겠죠?
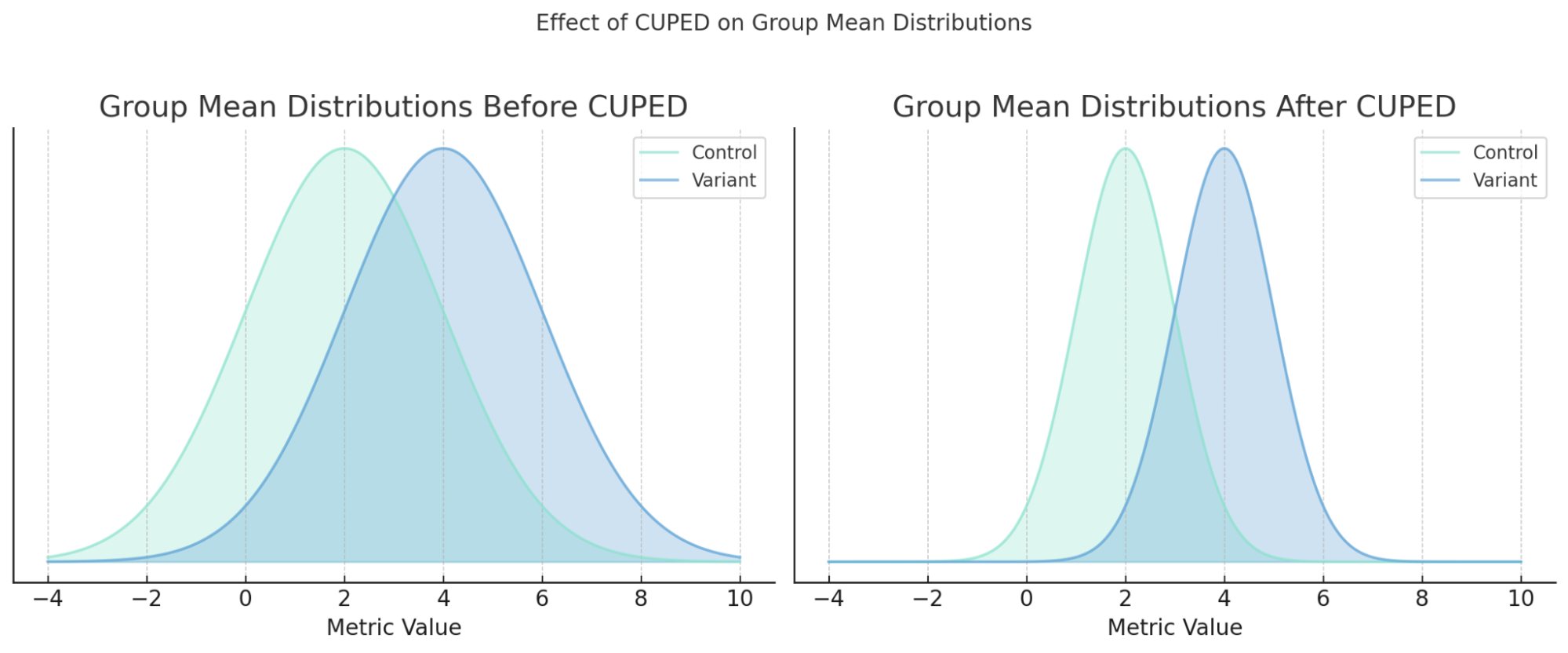
위에서 언급한 문제를 방지하기 위해서는 분석 지표를 사전에 정의하는 것이 중요해요. 여기서 핵심은 실험의 목적과 가장 연관된 주요 지표를 선택하는 거예요. 전환율이 목표라면 클릭률보다는 실제 구매 전환 데이터를 분석하는 것이 더 적합하겠죠. 주요 지표를 미리 정의하고, CUPED(Controlled Experiments by Utilizing Pre-Experiment Data)와 같은 분석 기법을 통해 실험 결과의 변동성을 줄이는 방법을 사용할 수 있어요.
✔️ CUPED(Controlled Experiments by Utilizing Pre-Experiment Data)
CUPED는 실험 시작 전에 수집한 데이터를 활용해, 실험 중 관측된 결괏값을 조정하는 기법이에요. 관측된 값과 사전 데이터 간의 상관관계를 분석해 결괏값에서 편향(bias)*을 보정하죠. 이렇게 조정된 값으로 실험 효과를 분석하면, 분산(variance)*을 줄여 신뢰도 높은 결과를 얻을 수 있어요. 쉽게 말해, CUPED는 고객의 "평소 습관"을 반영해 새로운 변화의 효과를 측정하는 방법이에요.
예를 들어, 이커머스 앱에서 새로운 추천 시스템을 테스트할 때를 생각해 볼까요?
- 고객 A는 평소 월 1회 구매하던 사람이 새 시스템 도입 후 2회 구매했다면, 이는 100% 증가한 거예요.
- 반면, 고객 B는 평소 월 10회 구매하던 사람이 11회 구매했다면, 이는 10% 증가한 거죠.
CUPED는 이런 개인별 구매 패턴 차이를 고려해, 실험의 실제 효과를 더 정확히 측정할 수 있게 도와줘요. 결과적으로 "이 증가가 정말 새로운 추천 시스템 때문인가, 아니면 원래 그 사람의 구매 패턴 때문인가?"를 구분할 수 있게 되는 거예요.
☝️CUPED 사용 시 주의할 점
CUPED를 사용할 때는 몇 가지 고려 사항이 있어요:
- 충분한 과거 데이터: 최소 몇 개월 치의 과거 데이터가 필요한데, 신규 서비스나 기능은 이런 데이터가 부족할 수 있어요.
- 분석 복잡성: CUPED는 일반 A/B 테스트보다 통계적으로 복잡해, 전문 인력이나 분석 도구가 필요할 수 있어요.
- 데이터 기간 선정: 너무 오래된 데이터는 현재 상황과 달라 결과를 왜곡할 수 있고, 너무 짧은 데이터는 일시적 특이 현상을 포함할 수 있어요. 적절한 기간의 데이터를 사용하는 것이 중요해요.
* 편향(Bias) : 예측이 실제 정답에서 얼마나 벗어나 있는지를 나타내는 값
* 분산(Variance): 예측 값들이 얼마나 변동이 큰지를 나타내는 값
|
|
|
<(좌) CUPED 적용 전/(우) CUPED 적용 후, 출처: STATSIG>
|
|
|
4. 의사결정 단계: 실험 종료 시점의 오류
실험 종료 시점은 의사 결정의 기반이 되는 만큼 신중해야 하는데요. 충분한 데이터를 수집하기 전에 실험을 조기 종료하거나, 반대로 통계적으로 무의미한 데이터를 계속 수집하는 경우가 발생할 수 있어요. 이럴 경우 결과의 신뢰도가 떨어지게 되고, 잘못된 결정을 내릴 가능성이 높아지겠죠?
이를 방지하기 위해서는 먼저 샘플 크기를 계산하여 실험에 필요한 최소 샘플 수를 정확히 산출하는 것이 중요해요. 이를 위해, 통계적으로 유의미한 샘플 크기를 계산하는 방법론(예: N-sample formula, power analysis 등)을 활용할 수 있는데요. 전환율 변화에 대한 목푯값을 정하고 이를 바탕으로 필요한 샘플 수를 미리 계획하는 거죠.
또한, 실험을 조기에 중단하는 것을 최대한 지양하고, 통계적 유의성*을 확보할 때까지 기다리는 인내심도 필요해요. 여러 테스트 결과를 종합적으로 검토하고 최종 결론을 내릴 때는 메타 분석(Meta-Analysis) 기법을 적용해 보는 것도 좋아요. 이를 통해 개별 테스트에서 드러나지 않은 패턴이나 인사이트를 발견할 수도 있기 때문이죠.😉
✔️ 메타 분석(Meta-Analysis)
메타 분석은 여러 실험이나 연구의 결과를 종합적으로 분석해, 보다 일반화된 결론을 도출하는 통계 기법이에요. 이를 통해 각 실험이 가진 데이터의 한계를 보완하고, 더 신뢰할 수 있는 결과를 도출할 수 있답니다.
쉽게 말해, 메타 분석은 여러 실험의 이야기들을 하나의 큰 그림으로 엮어내는 과정이라고 할 수 있어요. 예를 들어, 비슷한 주제로 진행된 5개의 A/B 테스트가 있다고 가정해 볼게요. 각각의 실험에서 통계적으로 유의미한 결과가 나오지 않았더라도, 메타 분석을 통해 결과를 종합하면 새로운 인사이트를 발견할 가능성이 높아져요.
메타 분석은 특히 다음과 같은 상황에서 유용해요:
- 샘플 크기가 작은 실험: 개별 실험의 데이터가 부족해 신뢰도가 낮은 경우, 여러 실험 데이터를 결합해 더 강력한 통계적 기반을 만들 수 있어요.
- 일관되지 않은 결과: 실험마다 결과가 다소 상반될 때, 메타 분석은 공통된 패턴을 찾아내는 데 도움을 줘요.
- 장기적인 트렌드 분석: 여러 실험 결과를 바탕으로 장기적인 사용자 행동 변화나 서비스 개선 효과를 추적할 수 있어요.
☝️메타 분석 사용 시 주의할 점
메타 분석을 사용할 때는 몇 가지를 주의해야 해요:
- 실험 간의 일관성: 각 실험의 조건과 맥락이 너무 다르다면 메타 분석의 신뢰도가 떨어질 수 있어요.
- 출판 편향(Publication Bias): 긍정적인 결과만 보고된 실험 데이터를 사용하면, 결과가 왜곡될 가능성이 있어요.
- 분석 도구 및 전문성: 메타 분석은 고급 통계 기법을 요구하기 때문에, 이를 수행할 전문 인력이나 도구가 필요할 수 있어요.
* 통계적 유의성(Statistical Significance)이란?
모집단을 추정하기 위한 가설이 가지는 통계적 의미를 말합니다. 즉, '통계적으로 유의하다'라고 하는 것은 확률적으로 단순한 우연이 아닌 통계적으로 차이가 있따는 의미에요. 그에 반해 '통계적으로 유의하지 않다'라는 것은 실험 결과가 단순히 우연한 현상으로 인해 발성한 것으로 통계적 차이가 없다는 의미에요.
* 출판 편향(Publication Bias)이란?
긍정적 결과를 가진 연구만 출판되는 경향으로, 전체 데이터의 공정성을 해칠 수 있는 문제를 의미해요.
|
|
|
파쓰 Talk🤓
오늘은 신뢰성 높은 A/B 테스트를 수행하기 위해 피해야 할 오류와 이를 보완할 수 있는 방법들에 대해 이야기해 봤어요. A/B 테스트는 단순히 데이터를 수집하는 과정이 아니라, 더 나은 의사결정을 내리기 위한 중요한 도구라는 점을 잊지 말아야 해요. 실험 설계부터 데이터 수집, 분석, 의사결정에 이르기까지 모든 과정에서 오류를 줄이고 신뢰도를 높이는 것이 성공적인 실험의 핵심이랍니다.
A/B 테스트의 결과는 비즈니스의 성공과 직결될 수 있어요. 따라서 올바른 실험 설계와 편향을 극복하는 방법을 활용해 신뢰할 수 있는 결과를 얻는 것이 무엇보다 중요하죠. 예를 들어, 넷플릭스는 A/B 테스트를 통해 맞춤형 콘텐츠 추천 시스템을 개발하며 사용자 참여율을 크게 향상시켰다고 해요.
파써분들도 오늘 소개한 팁들을 활용해서 신뢰도 높은 실험을 설계하고, 성공적인 결과를 만들어 나가시길 바랄게요! 😊
|
|
|
이번 주 파쓰가 엄선한 주요 테크 블로그 소식을 알아볼까요? |
|
|
1️⃣[SK플래닛] 오픈소스 Trino를 활용한 전사 데이터 분석 시스템 구축기
SK 플래닛의 빅테이터 플랫폼인 DIC(Data Integration Cluster)에서 진행한 실시간 데이터 전달 강화 프로젝트를 진행했다고 하는데요. 이번 프로젝트에서는 스트림 데이터의 실시간 처리와 오픈소스 Trino를 전사 데이터 분석 엔진으로 활용하여 데이터 전달 시간을 획기적으로 줄였다고 해요. 이번 글에서는 Trino를 활용한 전사 데이터 분석 및 조회 시스템 구축 사례에 대해 자세히 설명해 주신다고 하니, 궁금하시다면 본문을 통해 확인해 보세요!
2️⃣[요기요] 요기요 검색에서 형태소 분석기의 한계와 극복
요기요 검색에서 사장님들이 본인의 가게가 특정 키워드로 검색되지 않아 문의하는 경우가 있다고 해요. 검색 엔진에 해당 가게의 문서가 색인이 누락되어 발생할 수 있지만, 종종 문서가 색인에 포함되어 있음에도 검색되지 않는 경우도 종종 발생하는데요. 이러한 문제에는 다양한 원인이 있지만, 오늘은 그중에서도 '형태소 분석기의 오분석'에 관해 Search Platform 팀의 정승한 님께서 설명해 준다고 해요.
3️⃣[컬리] 서버리스에서 쿠버네티스로 - Airflow 운영 경험기
컬리에서는 수많은 데이터 파이프라인과 MLOps, BI(Business Intelligence) 등 다양한 분야에서 워크플로 관리 플랫폼인 Airflow를 사용하고 있는데요. 최근 그중 데이터 파이프라인에 사용하던 Airflow를 관리형 서비스에서 Kubernetes(이하 K8S) 환경으로 이관을 진행하고 안정적인 운영을 위한 여러 작업을 진행했다고 해요. 컬리의 Airflow 운영 경험기가 궁금하시다면 본문을 통해 확인해 보세요!
|
|
|
파쓰레터
오늘도 플랫폼 지식 +1 얻으셨나요?
다음 소식도 기대해 주세요~! |
|
|
|